![]()
In this post, I want to talk about my experiences at a remote co-op and lessons that I will take into my future co-ops and career.
What is PerkinElmer?
PerkinElmer is a multinational biotechnology firm that is focused on creating tools for scientists. Based in Massachusetts, PerkinElmer has a growing office in the Waterloo region that is focused purely on the application of AI for their scientist clients.
This was a opportunity that I was extremely excited for as most of my past experience directly lines up with the mission and goals of PerkinElmer. It was also an incredibly formative experience as I finally learned about the mysterious world of deep learning and got my hands, arms and feet dirty with CNNs.
What did I do?
I will try to be as general as possible to prevent violating my NDA terms but here is a general overview of the problem I was working on. I think the project is particularly relevant given the whole discussion around a vaccine for coronavirus.
Finding drugs and vaccines for diseases requires a lot of effort. The search space for molecules that could potentially render a disease useless is almost infinite if you consider synthetic molecules. However, even when certain compounds are screened and determined to be potentially useful, the medicine has to go through rigorous testing with several phases, trials and levels of approval. All in all, drug discovery is an incredibly time and effort-intensive problem.
Of course, scientists want to find any way possible to shorten this period, which is why they came up with the method of high content screening. High content screening screens several drugs at different concentrations and notes how these differing concentrations affects a cell. However, what is more interesting is that we can compare a cell’s morphological changes from a drug compound to the effect a disease has on a cell. If we can match effects of a compound with the disease, we potentially have a drug that we can use.
Consider the following example: let’s say disease A attacks our cells and destroys the endoplasmic reticulum in certain ways. If we can find a compound that does the opposite (i.e. restores the endoplasmic reticulum), we have found a potential drug.
Currently, there are high content screening machines that take images of cells and extracts numerical features, which are then used by scientists for their own drug discovery processes. During the first month, I was focusing on certain ML techniques that we could use to summarize and speed up the numerical feature detection processes, but then switched into using CNNs to analyze the images themselves for potential solutions.
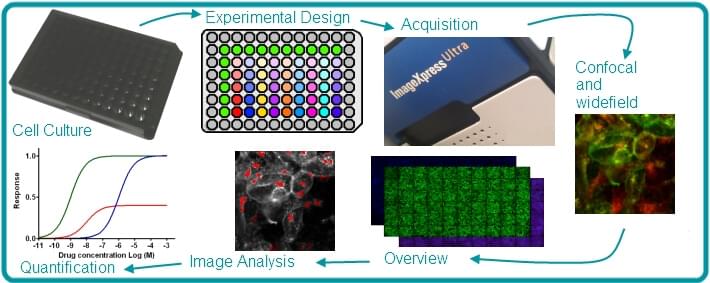
This co-op, unlike some of my past experience, required me to think of the end user at every step. While I was making the image analysis pipeline with the CNN, I had to include features that allowed the scientists to understand the model’s predictions and also easily run the pipeline. I liked this change, as I could easily understand how my work will affect the end user in improving their drug discovery processes.
A Reflection
For a first co-op, this was beyond my expectations. I regularly worked with people across the globe, especially from Latin America and Spain. Everyone was incredibly friendly and encouraging when I had a particular idea. I remember a particular example: our team wanted to create a tool to visualize cells, which is inherently difficult as cells are imaged using 5 channels, not 3 like regular RGB images. I spent weeks building a tool using the industry standards, but they are absolutely horrendous. I recommended to my boss and my boss’s boss to use an untested Python package rather than the industry standard; it worked beyond my expectations! This culture of encouraging innovation was something I really appreciated.
My only gripe with this experience was ML research. I have realized that I am more of a user-facing guy; I like to see the impact that my work has on regular people. Yes, I had to communicate with scientist clients frequently but it was usually about specific product requirements rather than pain points. I want to explore a more product-facing role in the next few internships rather than ML research which I have done for quite a few years now.
For anyone who is thinking about interning at PerkinElmer, I would definitely recommend it if you want to gain some knowledge on AI and partake in ML research.
Some Lessons
There were several lessons that I learned from this co-op, both in a professional and personal lens.
- Data is more important than models: I knew that this was a general rule of thumb in data science and have experienced this in other projects, but spending weeks improving my pre-processing pipeline really showed me the importance of data quality. To give a specific example: I accidentally assumed that the images I was using was 8 bit encoded (i.e. every pixel is represnted from 0-255), but it was actually 16 bit encoded (0-65k values for each pixel). When I recognized this, the model intrepretability was much clearer. Always do an exploratory analysis of your data and answer questions before you jump into the fun modelling.
- Math is important in machine learning, to an extent: There are two camps of thought when it comes to the importance of math in machine learning. One believes that you have to be well-versed in mathematics while others believe that you just need practical experience. The reality is much less polarizing. Developing original model architectures does require some mathematics to understand how the model works, but it also requires practical experience knowing whether the model is feasible to implement. On a practical perspective, math really helps when it comes to debugging model performance and determining the steps that you will need to take to get the model to a global optimim. I will give a specific example from my work: I often ran into issues with my interpretability pipeline. Having a good knowledge of multivariable calculus and the meaning of backpropagation and gradient descent helped me identify issues and work to correct issues as necessary.
- The best way to learn machine learning: this term was the fastest I ever learned machine learning. Prior to this term, I had never touched deep learning models and had to ramp up to create and run my own CNNs in just 2 weeks. I admit, my past experience in ML helped significantly, but I used a framework that I believe anyone can use. Most of this seems like obvious steps from a technical reader’s perspective, but I hope those who are new to this exciting world will take something out of the following :
- Do an online course: Andrew Ng’s course is good to understand the basics of ML but it is outdated (i.e. no one uses Octave to create models). Instead, look into fast.ai, Udemy deep learning courses or Andrew Ng’s newer courses. Kaggle also has some great deep learning courses.
- Pay attention to the math: understanding partial differentiation and the basics of linear algebra is vital to being successful in this field (as I mentioned in my above point). If the instructor talks about how weights and biases are combined to create a prediction, note that down!
- Create a project: once you feel that the utility of the course is decreasing, switch to creating projects. Use Kaggle’s introductory challenges or the most popular datasets to help you out (MNIST, CIFAR).
- Note unintuitive things down: if you feel that there is a particular aspect of machine learning you don’t understand, write it and move on. Once you are done with your task, research the problem further. For example, I didn’t fully understand the point of ReLU, tanh and other activation functions. However, a couple of YouTube videos helped me out.
- Details are extremely important in ML: this is the lesson that I will take away from my awesome supervisor. She is possibly the most detail-oriented person I have met and I have seen how this can lead to massive benefits. For example, when we were debugging our intrepetability pipeline, she was not satisfied with an explantion along the lines of “package X is not fit for our use case, let’s try something else.” She encouraged me to look at each and every step and we soon hit on a problem with image encoding. It’s easy in the ML world to say that we don’t understand how the models work and thus we don’t understand the errors that pop up. However, that’s the challenge of ML: dig through everything to find the root cause. Errors like these might cause irreperable damage, given how ML is used everywhere. Model mistakes that you attribute to the black box may in fact cause severe societal and scientific problems in the future.
- Create your own opportunities: I feel that many interns are afraid of experimenting; after all, we were hired under the good graces of our employers. However, my supervisor encouraged me to take risks and explore my own ideas if I thought it had some value. For incoming students at UWaterloo, understand that you are evaluated each co-op term and risk-taking/entrpreneurial spirit is a significant aspect of the evaluation. That being said, create your own path in your chosen companies and take those risks!