
Almost every developer can recognize the logo above. MongoDB has made a name for itself as one of the premier NoSQL databases and has created an interesting business model around hosting databases for different purposes, from small projects to large companies.
I was first exposed to MongoDB when I dived deep into Justin Trudeau’s speeches and used NLP to analyze the Prime Minister’s speeches. Specifically, I used MongoDB to store a bunch of massive text extracts from the Prime Minister’s official website. I was immediately taken aback by Mongo: it was incredibly easy and intuitive to use, even for a beginner developer like myself. As I pursued internships, I had this same feeling over and over again as I worked with the NoSQL database.
I wanted to give myself a challenge by doing a product analysis on a developer tool. It’s a technology that I am deeply familiar with technically, but not as familiar from a product perspective. Hopefully by the end of this post, I will have a much better understanding of the tactics and strategies that product managers will have to take into account when building developer-focused products.
The Magic of NoSQL
Let’s try to build some of our system design skills (a crucial skill for software engineers) and explore NoSQL databases.
Before we start with begin, let’s talk a little about databases. Databases are where we store data in the form of tables. A good analogy would be Excel spreadsheets: the spreadsheet file itself is a database while the spreadsheets within the file are individual ‘tables’ with related information.
The prevalent form of databases are relational databases. In this system, each table has the ability to have relations with other tables. For example, if we had a table for all the students at a university and another table for all the classes available for that university, we will have relationships between students and classes that describe the classes that students are taking. Primarily, the language to query these tables and find these relations is SQL (side note: if you have even an inkling of interest in data, please learn this language! It’s quite simple but there are massive benefits).
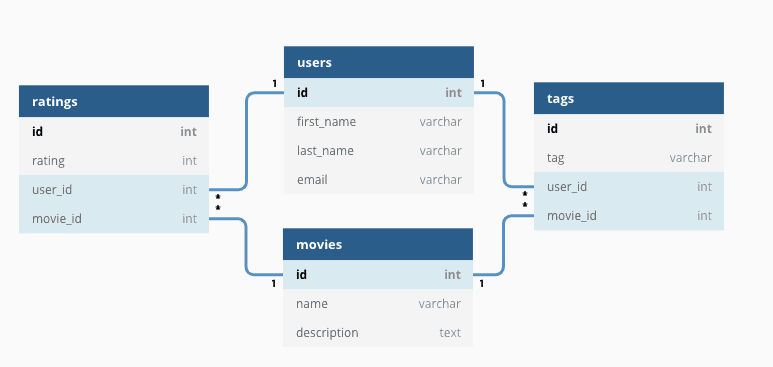
A couple of important points for relational databases:
- Each table relies on a schema, which essentially designates the columns for each table. If a new data row has an aberrant schema (eg. more/less columns than the schema, have integer columns instead of string columns), our table won’t accept the row
- Relational databases are ACID compliant. ACID is an acronym that stand for the following:
- Atomic: if I try to enter a row in a table, I will either enter the entire row or I will not enter anything. I cannot have partial rows in the table.
- Consistent: If I try to enter a row in a table and it succeeds, I am guaranteed that the table will have the exact same structure. In essence, each addition/change is guaranteed to move the table from a good state to another good state (never to a bad state)
- Isolated: If I try to change multiple rows in the table at the same time, the operations will not affect each other.
- Durable: The data I enter into a table will be in some sort of persistent storage, like a text file. This means that even if the database crashes, all my data is still in files on a hard disk somewhere.
This seems great, right? All the data is neatly organized, they have the same intra-table structure and we can find relationships easily. As always, there are issues.
Let me introduce the most important concept in system design: scalability. When we design databases, web servers, or any other type of infrastucture, we have to think critically whether our design can handle millions or even billions of users at the exact same time. With software eating the world, scalable design is more important than ever. This is the reason why relational databases have issues.
Let me give a simple example. If we are building a database for a high-growth company, we can’t have the database in 1 server because the server would get overloaded with hundreds of thousands of requests coming in per second. We would need to build more servers and try to distribute the database across servers. However, how do we ensure that a user entering data on server A is not affecting another user’s actions on server B? Can we design a truly isolated relational database? It’s really difficult! Forget about all those relations too…it would take forever to query data like this across different servers while maintaining beloved ACID properties.
Enter NoSQL. This database paradigm is much more relaxed. Instead of tables, we have collections. Instead of rows, we have documents. Each document can have any number and types of fields, meaning that documents in 1 collection may not necessarily have the exact same structure. Furthermore, non-relational databases are not ACID compliant. This is alright as long as engineers can handle this correctly. All of these loose requirements mean that NoSQL databases are much easier to scale across servers, helping companies serve millions of people without breaking a sweat.
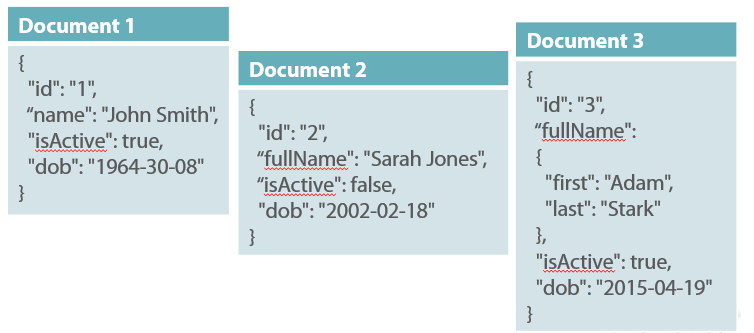
NoSQL technology has enabled companies like Uber, Amazon and Wish to scale immensely. It’s here to stay and will grow as our world incorporates technology everywhere.
MongoDB: Growth and Challenges
MongoDB was founded after the founders faced the exact same gripes that I just talked about. The team originally was part of DoubleClick, an Internet advertising company, during the early 2000s. This was the time when Internet was taking off and huge swathes of the human population were getting access with the advent of personal computing. Unfortunately for the founders, this meant that DoubleClick was often overwhelmed with the amount of requests and data it had to track. As we previously talked about, traditional relational databases aren’t a great solution for the issue of massive scaling.
The founders created MongoDB as a solution for their problem and eventually spun it off as a separate company. Since their founding, the company has grown to a $17.2B valuation. What’s strange about their story is that MongoDB is open-source: all their source code can be found on GitHub!
MongoDB’s clientele includes massive software companies like Google and Intuit, big banks like Royal Bank of Scotland, and even governmental departments like the Department of Veteran Affairs in the U.S. Given that MongoDB is the dominant leader in NoSQL database solutions, I imagine that MongoDB is poised for even more growth.
As I worked with MongoDB in my personal projects as well as industry, I became more acquainted with the state of database technology. These explorations revealed to me that MongoDB is facing some challenges that new products/improvements will need to address:
- The rise of AWS: AWS is playing the game of switching costs: it is developing an ecosystem of developer tools, making it very hard for other companies to compete as companies are unwilling to step outside the AWS ecosystem. AWS is now offering NoSQL based solutions like Aurora and DynamoDB alongside popular storage (S3), data engineering (Kinesis & EMR) and hosting (EC2 & ECR) solutions, which aims to knock MongoDB off the pedestal. Amazon’s strategy of turning every single internal tool, pain point and cost into a product is brilliant and it’s hurting companies like MongoDB.
- Other tech companies: open-source tools like Apache Cassandra (published by Facebook) and companies like CockroachDB and CouchbaseDB are offering scalable solutions, following in the successful path of Mongo by selling databases-as-a-service
- New use cases: with software eating the world, we are seeing data coming from relatively newer places, such as IoT and mobile devices. Furthermore, we are seeing more software startups with many different approaches to problems that we face in life. A one-size-fits-all solution like Mongo may not be the best approach anymore.
- Evolution in the data ecosystem: Data is so much more than storage. It’s also about moving and transforming data in the right way in order to gain competitive advantages. We are seeing a massive growth in data and machine learning engineering because of this growing problem
All in all, MongoDB has reached domination but is facing attacks on all sides. Let’s see if we can think of a product to address some of these challenges.
Users
Let’s start by analyzing the potential users of MongoDB and prioritize who we should focus on. Here’s my breakdown of users:
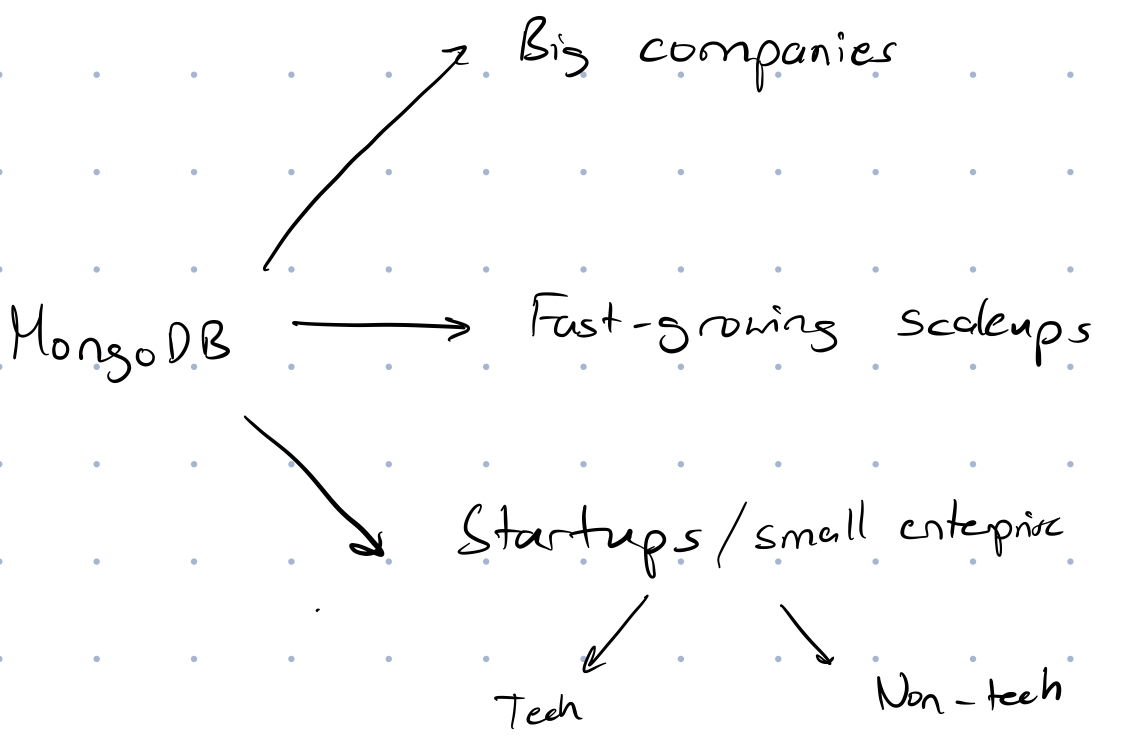
To explain briefly:
- Big companies: think FAANG and large unicorns like Stripe and Uber. They are using MongoDB and other NoSQL solutions to reliably scale to hundreds of millions of users
- Fast growing scaleups: think Notion and Chime. These companies are in hypergrowth phase and depend upon massive growth to survive, hence the need for NoSQL solutions.
- Startups/small-enterprises: These are companies that are pre-product/market fit or just reached some initial revenue milestones. We can further segment them into tech startups and non-tech startups.
Given MongoDB’s challenges, I want to prioritize tech startups for the following reasons:
- Switching costs: if you develop a highly-functioning ecosystem for a company earlier on, it will become very difficult to switch out of the system because there is a lot of migration to be done. Put simply, it’s not worth switching out. By targeting smaller companies, MongoDB can build an ecosystem that makes it tough to switch out later on, building long-lasting loyalty. This is a defensive strategy to combat AWS, which uses the exact same playbook. This is why it’s important to target young companies.
- Unique data needs: we have seen AWS and other DBaaS (database as a sevice) providers target large companies, which makes it difficult for startups to use their technology to meet their unique needs. For example, building data engineering infrastructure to populate AWS Redshift warehouses takes time, the most valuable resource for startups. There is no good solution for startup data needs
- Scalable solutions: technologies that are made for startups that are particularly popular can easily scale up to larger companies, who may have the same issues on a larger scale. Given that MongoDB’s technology is meant exactly for this situation, this is particularly good reason for targeting startups.
Pain Points
Scouring the Internet for founder stories about their experiences dealing with data and pooling from my own struggles, I compiled 4 major painpoints:
- Data engineering: how do we move data from one place to another? How do we also make sure that we do it in a scalable fashion and transform our data into something useful? These are questions startups are constantly wrestling with and can possibly make or break the young company. These are the specific data engineering sub-painpoints:
- Connecting different sources: as a startup, you will have logging tables, derived tables, and final tables that analysts and non-engineering folks can look at. Connecting all of these is intimidating and hard, but necessary
- Visualizing the data structure: data quickly becomes messy (especially if you are just dumping tables into data lakes), so seeing how tables are connected to each other becomes pretty important. This is a new trend in data engineering (eg. Amundsen, Querybook, Metacat) but hasn’t trickled to startups yet although they badly need it
- Logging tables: setting up tables to log every interaction with users while excluding bots and also setting up streaming infrastructure is difficult. These are needed to populate the relational tables that analysts use to dictate company strategy.
- Best practices: as mentioned in Blitzscaling, running a startup is akin to building a rocketship as you jump off a cliff. Given that speed often comes at the cost of best practices, we eventually have a messy set of data principles that can land the company in hot waters (think data leaks) or even cause the demise of the business
- Visualizing data: dashboarding software is always needed to help founders make decisions for their company
- Setting up data infrastructure: this is a very broad pain point that ties into the first pain point. Startups often don’t really understand what database technologies/frameworks they need. There is a lack of information for small companies since most data challenges are seen by large companies. However, as more and more startups come into vogue, getting the right data infra early on is a massive advantage
To prioritize these painpoints, I looked at the frequency and intensity of each pain point and plotted them out:
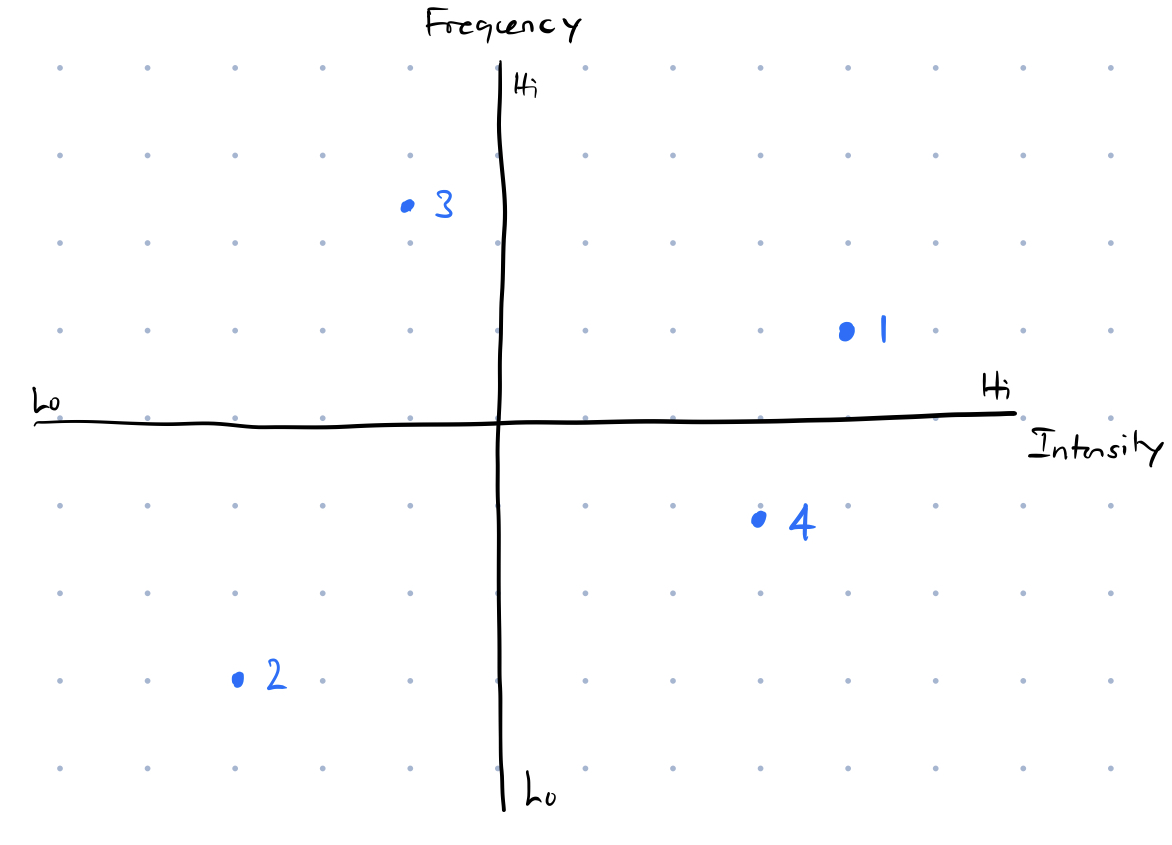
Given these tradeoffs and our strategy of building switching costs to counter AWS, it would make most sense to focus on the data engineering pain point and build out the best data engineering ecosystem for startups that can easily scale as startups grow.
Solutions
I’ve come up with three possible products that Mongo could develop to address the data engineering pain points of startups:
- Mongo Flow: to address the challenges of connecting different sources and transforming data, many companies use Airflow, which is an orchestration framework that runs data pipelines at set intervals. This makes the lives of data engineers incredibly easy as it is very easy to see how derived tables are created. There is no equivalent for NoSQL databases, which Mongo could capitalize on. This solution should also make use of the unique benefits of NoSQL when building data pipelines
- Mongo Graph: this product visualizes the connections between Mongo collections (connections being pipelines) in a graph-like manner. This addresses the pain point of visualizing data as it continues to scale. The product should also have the ability to see how SQL tables are connected in the data ecosystem
- Mongo Start: Shopify did not becomes successful because they launched a snowboard store; they became successful because they created a platform for anyone to easily create an e-commerce store. This is the key revelation that propelled their growth. Similarly, MongoDB could learn from the Canadian company and build a platform which makes it easy for developers to start data engineering. This product would be an opinionated data infrastructure framework that pre-populates logging table structures, derived tables and pipelines.
Let’s now prioritize and choose one. There are two criteria that we need to consider:
- Will this capture young companies at a greater-than-average rate?
- Is the engineering effort worth the potential reward?
Given these criteria, I would prioritize Mongo Start. This is the solution that can immediately lock a startup into the Mongo ecosystem. My only concern is that this requires a lot of engineering effort, as it requires work to build generalizable infrastructure. If the engineering effort is too high, I would prioritize MongoFlow. It may not have the greatest value proposition for younger companies to join the Mongo community, but it offers enough value for existing startups, which could potentially increase refferal rates into the Mongo product. It is also an easier engineering challenge than Mongo Start, as it focuses on one part of the data engineering lifecycle.
Metrics
After reading a couple of posts regarding metrics for developer products, I prioritized four metrics that I would use to monitor success for Mongo Start.
- Time to working app (adoption): we can use this to measure the ease of building with Mongo Start and also understand which features are not as useful (as the time would not include those features).
- Daily active tokens (usage): Assuming that developers are using tokens to build on our platform, we can monitor this to understand usage patterns (a direct parallel with daily active users). I chose daily rather than weekly or monthly because I would expect that the user would use the technology at least once a day
- 90th percentile latency (usage): speed is extremely important for developers, so monitoring the slowest latency can help us improve application performance.
- Cohort retention by language (retention): we can use typical measures of churn using developer tokens, but it would be interesting to day 1, day 30, day 60 and day 90 retention to understand whether the product is truly sticky as well as segment by programming language.
Growth is the most important aspect of this app, as we are trying to build switching costs as fast as we can. Thus, daily active tokens would be the North Star metric.
Conclusion
In order to tackle the challenges of increasing competition and unique needs in the NoSQL data world, we decided to focus on small startups in order to lock them into the MongoDB ecosystem. We prioritized Mongo Start, an opinionated data infrastructure framework so startups can quickly bootstrap a data infrastructure that they can easily build off as they scale up.
I had a lot of fun thinking through this post. Combining my experience in data, system design and product was a really interesting exercise. Please let me know if you have any suggestions/questions about my approach!
References
https://www.mongodb.com/company https://www.moesif.com/blog/technical/api-metrics/API-Metrics-That-Every-Platform-Team-Should-be-Tracking/