In this post, I want to discuss my experiences at my second co-op and some of the takeaways during these past 4 months.
What is Data Engineering?
I was originally recruited by Wish as a data scientist. This was a field I knew fairly well. However, I was actually placed on the Data Engineering team and given the choice to switch into data science. I decided to stick with data engineering as I wanted to learn about this impactful field and diversify my skills.
Like many people, I didn’t have a great understanding of data engineering; however, after a few months of work and diving into data infrastructure, I have come to understand why data engineering is so important. This subset of software engineering is really the foundation of companies that are as data-driven as Wish. With almost every single product decision being made through metrics, it is absolutely crucial that our data infrastructure can handle millions of data points daily and make the correct calculations to inform end users. Data scientists, ML engineers and even product managers cannot really function without proper data engineering practices.
A data engineer’s responsibilities are broadly divided into two areas:
- Storage: where exactly is data being stored?
- Movement: how should data move from a source to a sink?
Let’s dive into storage first. There are several parts of an application that generate data (eg. logs, user interactions, merchant interactions) and data engineers are responsible for creating a scalable solution to store massive amounts of data. Furthermore, there are often derivative data tables made from the original data logged in a database, since the logging tables are not that useful for PMs or data scientists. These tables also need to be stored somewhere safe and scalable. Concepts related to data storage include: partitions, data lakes, data warehouses, sharding, and distributed databases. Here are some common technologies that are used in data storage:
- AWS S3: the industry standard for data storage. You can store any type of data in buckets and partitions. You will see AWS repeated several times in this post because it is one of the most scalable solutions for data (AWS = Amazon Web Services).
- AWS Redshift: a structured data warehouse stored in AWS
- MongoDB: a NoSQL database
- Snowflake: another data warehouse solution
- AWS RDS: a relational database also stored in AWS
- Apache Hive: data warehouse solution built on Apache Hadoop, which is a software that enables data computing across several different computers (known as distributed computing)
- Apache Cassandra: another NoSQL solution
- MySQL: an old but extremely reliable and simple database. Old but gold!
Movement is a slightly more interesting topic. Data movement can be broadly divided into stream (real-time data pushes from data publishers to data consumers) and batch processing (gather all relevant data at particular times, kind of like pulling data from sources). This part of a data engineer’s job is also one of the most challenging aspects of the role as transporting terabytes of data daily can be a big challenge. The main concept in data transmission is the ETL pipeline: extract data from a source, transform it using SQL and store it in some partition. Here are some common technologies in the data transmission space:
- Apache Spark: a SQL engine built for distributed data processing. Fun fact: Spark is actually created by a UWaterloo grad!
- Apache Airflow: I was living and breathing Airflow for a few months during my internship. Airflow schedules ETL pipelines. However, you can specify complex relationships in your ETL pipeline by codifying directed acyclic graphs, or DAGs. Here’s a simple example of a DAG:
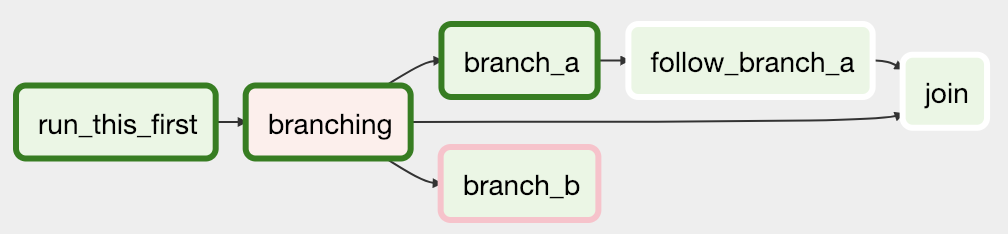
- Apache Kafka: this is a streaming solution that allows you to consume data from a bunch of publishers. Extremely useful for real-time data analytics
- AWS Kinesis: AWS’s answer to Kafka
- Presto: High performance SQL engine that can query multiple sources.
All of the above were new to me, so you can imagine that my growth rate was immense. Working on several parts of Wish’s data infrastructure taught me a lot about why data engineering is so important. I firmly believe that data engineering is as important or even more important than data science and ML. This is what makes or breaks a company.
What did I do at Wish?
From my time at Wish, I was blown away by how much impact I was able to make as an intern. Interns are treated like full-time employees and are often given a lot of full-time responsibilities. These responsibilities greatly accelerated my growth as an engineer.
As part of the data engineering team, I was specifically building data infrastructure to support A/B tests on all logged-out users to the Wish platform. Let me break this down a little bit.
If you’re not already aware, tech companies love to experiment. Using experimental results and data, companies will integrate these findings into their product roadmap and ship features. For many tech companies, this often manifests in testing different versions of their product to different sets of users and monitoring how key metrics change as a result of these different versions.
Let me give a simple example. Instagram Reels has been a popular addition to the Facebook-owned platform. Many people think that Facebook just decided to implement it due to the success of TikTok, but it is a little but more nuanced than that. Facebook rolled out Reels to a percentage of their Instagram users (let’s say 10-20%). Facebook then looked at how key metrics were changing within this experiment group and the rest of the users (known as a control group). The company probably found that metrics like daily active users, watch time and ad impressions went up significantly in the experiment group compared to the control group. Armed with this knowledge, Facebook decided to go ahead and launch Reels to everyone.
Like most tech companies, Wish uses A/B testing to find out whether a product hypothesis is worth launching to everyone. I was responsible for building and maintaining many of these data pipelines and took ownership over all pipelines responsible for calculating metrics for logged-out users.
Asides from data engineering, I was also responsible for launching new features and massive performance improvements on our internal portal to view all A/B testing results for hundreds of experiments. An example of a feature I launched was a universal metric viewer that enables product managers and data scientists to view how all experiments are impacting a single metric, preventing experiment cannabilization and over-optimization.
Some of the technologies that I used on a daily basis include:
- Airflow
- SQL (Spark, Presto, Hive) x100. I used a LOT of SQL
- MongoDB
- Tornado (a Python framework used for asynchronous web applications)
- Redshift
- Kubernetes (fun fact: Kubernetes is also known as k8s, which is a numeronym as there are 8 characters between K and s in Kubernetes. Another famous numeronym is a16z for Andreessen Horowitz. I was mindblown when I figured this out)
This role was really neat and merged my interests in engineering, statistics and product. I got to understand the importance of solid data practices and the importance of experimentation in industry and will take many of these skills to future co-op
Reflection and Lessons
Overall, I found the W21 Wish internship to be a stellar experience. I have quickly realized that my satisfaction with my work is directly correlated with the amount of learning I am able to do; fortunately, I was able to optimize for growth this term and enjoyed my work tremendously.
Data engineering also got me thinking about the hierarchy of data in companies. Here’s a diagram that captures my thoughts on this subject:
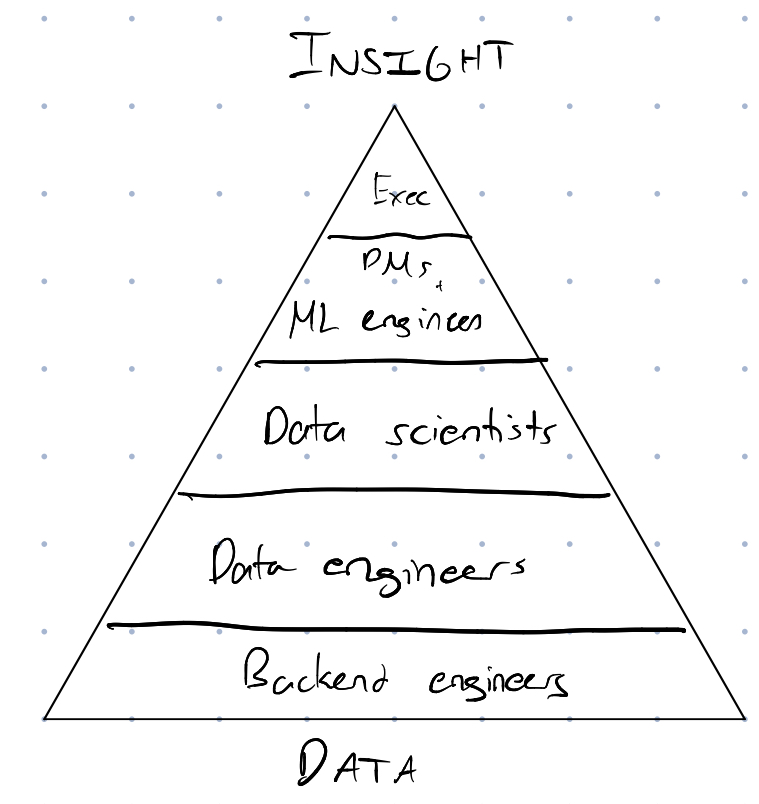
I can’t judge how this hierarchy relates to the relative importance for each role. We can’t judge a role solely by how well it can interact with data, because many roles in a company aren’t quite related to data at all (eg. sales, strategy). I do believe that students are mostly exposed to the top half of the hierarchy, but the bottom half is equally important and holds up the insights that the company depends upon. I highly recommend people interested in a career involving data to seek out opportunities to intern as a data engineer. If you do decide to move up the hierarchy, you will have valuable skills that can immensely help your decision making.
Some takeaways from my internship:
- Distributed systems are really cool: Like all other interns, I went through some onboarding at the beginning of the term where I learned about the internal architecture of Wish. It was fascinating. I realized that much of the concepts that are needed to really understand a distributed system are not really taught in software engineering core courses, so I decided to self-study a lot of it while also applying my knowledge in co-op. I truly believe this is the epitome of software engineering and more students should learn about the field. This is a great talk that explains how engineers tackled enormous scaling challenges with their distributed system at Pinterest.
- Treat your analytics like a product: I was involved with many of the decisions that we made regarding our internal A/B testing tool. These discussions were extremely similar to how PMs analyze and determine product strategy, albeit with more engineering twists. I realized that a focus on the end-user for all products, even internal ones, is extremely useful and solves a lot of problems moving forward.
- If you even touch data, use SQL: I spent an extraordinary time writing performant SQL and looking at the various idiosyncrasies for each query engine (eg. broadcast joins in Spark, Hive MapReduce). To sum it up, just learn SQL. Even if you don’t really want to work with data in the future, it is an incredibly important skill and underpins a lot of modern applications today.
- Internal networks: many of us think of networking as solely an external activity, i.e. networking with strangers or mutual connections. At Wish, mentors advised that I talk to people that I thought were doing interesting things. Putting myself out there was tough, but I was able to meet some really cool individuals and learn a lot more about product management at Wish. To students coming into new jobs, try meeting new people every week: you never know what you will learn.
Overall, I had a great time at Wish and would highly recommend the internship to any student.